Text2Shape: Generating Shapes from Natural Language by Learning Joint Embeddings
Kevin Chen, Christopher B. Choy, Manolis Savva, Angel Chang, Thomas Funkhouser, Silvio Savarese
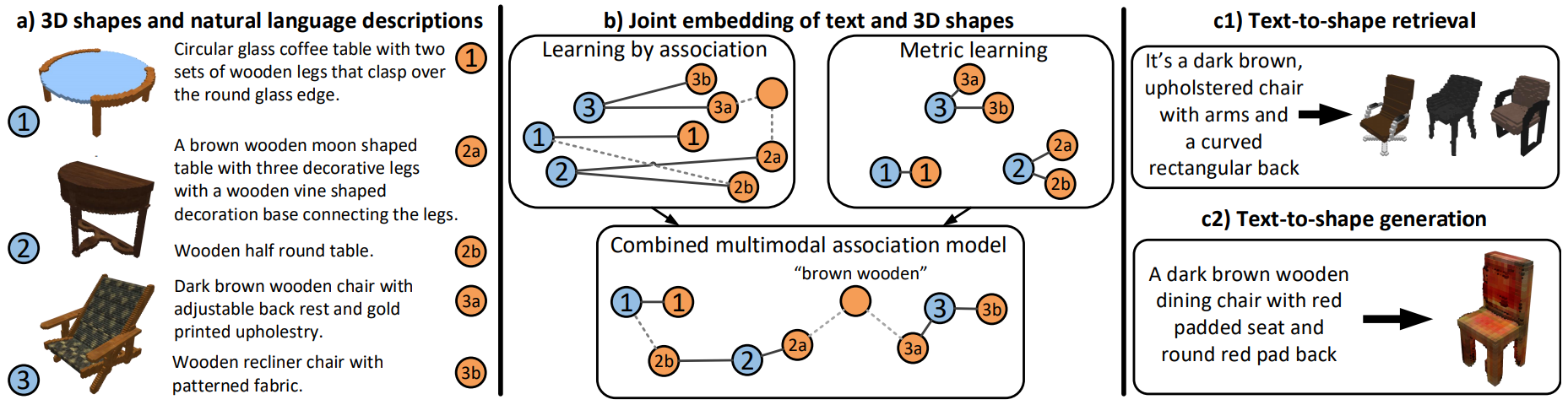
Overview
We present a method for generating colored 3D shapes from natural language. To this end, we first learn joint embeddings of freeform text descriptions and colored 3D shapes. Our model combines and extends learning by association and metric learning approaches to learn implicit cross-modal connections, and produces a joint representation that captures the many-to-many relations between language and physical properties of 3D shapes such as color and shape. To evaluate our approach, we collect a large dataset of natural language descriptions for physical 3D objects in the ShapeNet dataset. With this learned joint embedding we demonstrate text-to-shape retrieval that outperforms baseline approaches. Using our embeddings with a novel conditional Wasserstein GAN framework, we generate colored 3D shapes from text. Our method is the first to connect natural language text with realistic 3D objects exhibiting rich variations in color, texture, and shape detail.
Links
If you find our project helpful, please consider citing us:@article{chen2018text2shape,
title={Text2Shape: Generating Shapes from Natural Language by Learning Joint Embeddings},
author={Chen, Kevin and Choy, Christopher B and Savva, Manolis and Chang, Angel X and Funkhouser, Thomas and Savarese, Silvio},
journal={arXiv preprint arXiv:1803.08495},
year={2018}
}
Video Summary
Dataset

ShapeNet Voxelizations
- ShapeNet chair and table categories only
- Colored RGB voxelizations
- Resolutions: 32, 64, and 128
- Surface (hollow) and solid voxelizations
ShapeNet Downloads
- ShapeNet Dataset [Webpage]
- Text Descriptions (CSV, 11MB) [Download]
- Solid Voxelizations: 32 Resolution (ZIP, 1GB) [Download]
- Solid Voxelizations: 64 Resolution (ZIP, 1.7GB) [Download]
- Solid Voxelizations: 128 Resolution (ZIP, 4.2GB) [Download]
- Surface Voxelizations: 32 Resolution (ZIP, 562MB) [Download]
- Surface Voxelizations: 64 Resolution (ZIP, 1GB) [Download]
- Surface Voxelizations: 128 Resolution (ZIP, 3.1GB) [Download]
Primitives Downloads
- Primitive Shape Voxelizations: 32 Resolution (ZIP, 49MB) [Download]
If any errors or artifacts in the dataset are found, please report them to kevin.chen@cs.stanford.edu. Thank you!
Note: We use solid 32 resolution voxelizations in our work.
Acknowledgements
This material is based upon work supported by the National Science Foundation Graduate Research Fellowship Program under Grant No. DGE – 1147470. Any opinions, findings, and conclusions or recommendations expressed in this material are those of the author(s) and do not necessarily reflect the views of the National Science Foundation. This work is supported by Google, Intel, and with the support of the Technical University of Munich–Institute for Advanced Study, funded by the German Excellence Initiative and the European Union Seventh Framework Programme under grant agreement no 291763.